Getting Started: Your Python and Jupyter Environment¶
Welcome to the world of Python for data science! This notebook will guide you through the basics of Python and its essential tools, setting you up for more advanced data analysis techniques.
To effectively run the labs and exercises in this book, you will need the following:
- Python 3 Installation: We’ll be using Python 3, the current and widely supported version of the language. Python is the workhorse behind many data science tasks, known for its readability and extensive libraries.
- Jupyter Notebook Access: Jupyter is an interactive environment that allows you to write and run code, visualize results, and document your process all in one place. It’s a fantastic tool for learning and exploring data.
Installing Python and Anaconda:
The easiest way to get both Python 3 and Jupyter, along with many useful data science packages, is by installing Anaconda. Anaconda is a free and open-source distribution of Python and R, specifically designed for scientific computing and data science.
- Download Anaconda: Go to anaconda.com and download the Python 3 version appropriate for your operating system (Windows, macOS, or Linux).
- Installation: Follow the on-screen instructions to install Anaconda on your system. Anaconda will install Python, Jupyter, and a host of popular packages like NumPy, Pandas, and Matplotlib, which we’ll be using extensively.
Accessing Jupyter Notebook:
Once Anaconda is installed, you have several options to access Jupyter:
- Google Colaboratory (Colab): colab
.research .google .com/ - Colab is a free cloud-based Jupyter Notebook environment provided by Google. It requires no installation and is a great way to get started quickly. Simply open your browser, go to the link, and you can begin coding. - JupyterHub: jupyter.org/hub - JupyterHub provides a multi-user Jupyter environment that can be accessed through a web browser. This is often used in educational or organizational settings.
- Local Jupyter Installation: If you installed Anaconda, you already have Jupyter installed locally on your computer. You can launch it in a few ways:
- Anaconda Navigator: Open Anaconda Navigator (installed with Anaconda) and launch JupyterLab or Jupyter Notebook from there.
- Command Line/Terminal: Open your command prompt (Windows) or terminal (macOS/Linux) and type
jupyter laborjupyter notebookand press Enter. This will open Jupyter in your web browser.
For detailed, up-to-date instructions on setting up Python and Jupyter, please refer to the “Python resources” page on the book website statlearning.com.
Installing the ISLP Package:
The ISLP package is specifically designed to accompany this book. It provides convenient access to datasets and custom functions that we will use throughout the labs. It also conveniently installs many other packages that are commonly used in data science.
To install ISLP, open your terminal or Anaconda Prompt and type the following command:
# %pip install ISLPPress Enter to execute the command. pip is the package installer for Python. This command will download and install the ISLP package and its dependencies.
For more information about the ISLP package, including documentation and available datasets, visit the ISLP documentation website linked from the “Python resources” page.
Running this Lab Notebook:
- Download the Notebook: Download the file
Ch2-statlearn-lab.ipynbfrom the “Python resources” page on the book website. This file contains the code and exercises for this lab. - Navigate to the Notebook Directory: In your terminal or command prompt, navigate to the directory where you downloaded
Ch2-statlearn-lab.ipynb. You can use thecdcommand (change directory) for this. For example, if you downloaded it to your “Downloads” folder, you might typecd Downloads. - Launch Jupyter Lab: In the same terminal or command prompt, type
jupyter lab Ch2-statlearn-lab.ipynband press Enter. This command will open Jupyter Lab in your web browser, and theCh2-statlearn-lab.ipynbnotebook should be open and ready to use.
Windows Users:
If you are using Windows, you can access Anaconda and its tools through the Start Menu. Look for “Anaconda Prompt” or “Anaconda Powershell Prompt” in your Start Menu. Opening one of these will give you a command-line interface where you can run the pip install ISLP and jupyter lab Ch2-statlearn-lab.ipynb commands as described above.
Let’s begin our Python journey!
Basic Commands: Interacting with Python¶
Let’s start with the fundamental building blocks of Python. Like any programming language, Python uses functions to perform actions. Functions are reusable blocks of code designed to carry out specific tasks.
To use a function, you “call” it by typing its name followed by parentheses (). Inside the parentheses, you can provide inputs or arguments that tell the function how to operate. A function can take zero, one, or multiple inputs.
One of the most basic functions is print(). The print() function displays the output of whatever you provide as its arguments to the console (or in the output cell of a Jupyter notebook).
print("fit a model with", 11, "variables")fit a model with 11 variables
In the code above, "fit a model with", 11, and "variables" are the arguments passed to the print() function. print() takes these arguments and displays them as text.
Getting Help with Functions:
Python provides a built-in way to get help and documentation about functions. To see the documentation for any function, you can type the function name followed by a question mark ? and run the cell.
print?Docstring:
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
Type: builtin_function_or_methodRunning this will display the documentation for the print() function, explaining its purpose, arguments, and usage. This is an invaluable tool for learning about new functions and understanding how to use them correctly.
Basic Arithmetic:
Python can perform mathematical calculations just like a calculator. Adding numbers is straightforward:
3 + 58Python understands standard arithmetic operators like + (addition), - (subtraction), * (multiplication), / (division), and ** (exponentiation).
Strings: Working with Text:
In Python, text is represented using strings. Strings are sequences of characters and are enclosed in either single quotes ' ' or double quotes " ".
"hello" + " " + "world"'hello world'Here, we are using the + operator to concatenate (join together) strings. Python treats strings as sequences, and the + operator, when used with strings, performs concatenation rather than addition.
Lists: Ordered Collections of Items:
Python lists are versatile data structures that hold ordered collections of items. Lists are defined using square brackets [] and items within a list are separated by commas ,. Lists can contain items of different data types (numbers, strings, even other lists!).
x = [3, 4, 5]
x[3, 4, 5]In this example, we’ve created a list named x containing the numbers 3, 4, and 5. When you type the name of a variable in Jupyter and run the cell, Python displays the value of that variable, which in this case is the list [3, 4, 5].
List Concatenation vs. Element-wise Operations:
Let’s explore what happens when we try to “add” two lists:
y = [4, 9, 7]
x + y[3, 4, 5, 4, 9, 7]The result might be surprising if you were expecting element-wise addition (like adding the first element of x to the first element of y, the second to the second, and so on). Instead, Python concatenates the lists, meaning it joins them end-to-end. This is because, in Python, lists are designed to hold arbitrary objects, not just numbers for mathematical operations.
This behavior highlights a crucial point: Python is a general-purpose programming language. While it’s powerful for data science, many data-specific functionalities come from external packages or libraries. For numerical computations and data manipulation, we’ll rely heavily on packages like numpy and pandas.
In the next section, we’ll dive into numpy, which provides efficient tools for numerical operations, especially with arrays and matrices. For more comprehensive information about basic Python concepts, you can explore the official Python tutorial: docs
Introduction to Numerical Python (NumPy)¶
As we’ve seen, standard Python lists are not optimized for numerical operations like element-wise addition or matrix manipulations. This is where NumPy (Numerical Python) comes to the rescue. NumPy is a fundamental library in Python for scientific computing. It provides powerful tools for working with arrays, matrices, and performing efficient numerical computations.
NumPy introduces a new data structure called the NumPy array, which is designed for numerical data and operations. NumPy arrays are more efficient and versatile than standard Python lists for numerical tasks.
To use NumPy, we first need to import it into our Python environment. It’s convention to import NumPy using the abbreviation np for easier access to its functions.
import numpy as npThis line imports the NumPy library and gives it the alias np. Now, whenever we want to use a NumPy function or object, we’ll prefix it with np..
Creating NumPy Arrays:
We can create NumPy arrays from Python lists using the np.array() function.
x = np.array([3, 4, 5])
y = np.array([4, 9, 7])Here, we’ve created two NumPy arrays, x and y, from the lists we defined earlier. Notice the syntax np.array(). This indicates that we are calling the array() function from the numpy package (which we’ve aliased as np).
Element-wise Operations with NumPy Arrays:
Now, let’s try adding our NumPy arrays x and y:
x + yarray([ 7, 13, 12])This time, the result is what we intuitively expected: element-wise addition! NumPy arrays are designed for numerical computations, and arithmetic operations like +, -, *, / are performed element-wise when applied to NumPy arrays.
Multidimensional Arrays (Matrices):
NumPy arrays can be multidimensional, making them ideal for representing matrices and tensors. A two-dimensional NumPy array is essentially a matrix.
x = np.array([[1, 2], [3, 4]])
xarray([[1, 2],
[3, 4]])This creates a 2x2 matrix (a two-dimensional array) represented by x. The outer square brackets [] enclose the rows, and the inner square brackets enclose the elements within each row.
Array Attributes:
NumPy arrays have various attributes that provide information about the array itself. You can access an attribute using dot notation: array_name.attribute_name.
For example, ndim attribute tells you the number of dimensions of the array:
x.ndim2The output 2 indicates that x is a two-dimensional array (a matrix).
The dtype attribute tells you the data type of the elements in the array.
x.dtypedtype('int64')The output int64 (or similar, depending on your system) indicates that the elements of x are 64-bit integers. NumPy arrays store elements of the same data type, which contributes to their efficiency.
Data Type Conversion:
NumPy automatically infers the data type based on the input data. If you provide integers, it creates an integer array. If you include a decimal number, it will create a floating-point array.
np.array([[1, 2], [3.0, 4]]).dtypedtype('float64')Here, even though most elements are integers, the presence of 3.0 (a float) forces NumPy to create a floating-point array (float64).
You can also explicitly specify the desired data type when creating an array using the dtype argument:
np.array([[1, 2], [3, 4]], float).dtypedtype('float64')This explicitly creates a floating-point array, even though the input values are integers.
Array Shape:
The shape attribute of a NumPy array returns a tuple (an immutable sequence) indicating the dimensions of the array. For a matrix, the shape is (rows, columns).
x.shape(2, 2)For our 2x2 matrix x, the output (2, 2) confirms it has 2 rows and 2 columns.
Array Methods and NumPy Functions:
NumPy arrays have methods, which are functions associated with the array object itself. You call a method using dot notation: array_name.method_name().
For example, the sum() method calculates the sum of all elements in the array.
x = np.array([1, 2, 3, 4])
x.sum()10Alternatively, NumPy also provides stand-alone functions that operate on arrays. For example, np.sum() function also calculates the sum of array elements.
x = np.array([1, 2, 3, 4])
np.sum(x)10In many cases, both methods and functions achieve the same result. Choosing between them often comes down to personal preference or code readability.
Reshaping Arrays:
The reshape() method allows you to change the shape of an array without altering its data. It returns a new array with the specified shape.
x = np.array([1, 2, 3, 4, 5, 6])
print("beginning x:\n", x)
x_reshape = x.reshape((2, 3))
print("reshaped x:\n", x_reshape)beginning x:
[1 2 3 4 5 6]
reshaped x:
[[1 2 3]
[4 5 6]]
Here, we reshaped the 1D array x into a 2D array x_reshape with 2 rows and 3 columns. NumPy fills the reshaped array in row-major order, meaning it fills row by row.
Indexing NumPy Arrays:
NumPy uses zero-based indexing, meaning the first element of an array is at index 0, the second at index 1, and so on. For multidimensional arrays, you index using comma-separated indices within square brackets [].
x_reshape[0, 0]1This accesses the element at the first row (index 0) and first column (index 0) of x_reshape.
x_reshape[1, 2]6This accesses the element at the second row (index 1) and third column (index 2).
Similarly, for a one-dimensional array:
x[2]3This accesses the third element (index 2) of x.
Views vs. Copies in NumPy:
A crucial concept in NumPy is the distinction between views and copies. In some cases, operations on arrays create views, which are just different ways of looking at the same underlying data. Changes to a view will affect the original array. In other cases, operations create copies, which are independent arrays with their own data.
Let’s see an example of a view:
print("x before we modify x_reshape:\n", x)
print("x_reshape before we modify x_reshape:\n", x_reshape)
x_reshape[0, 0] = 5
print("x_reshape after we modify its top left element:\n", x_reshape)
print("x after we modify top left element of x_reshape:\n", x)x before we modify x_reshape:
[1 2 3 4 5 6]
x_reshape before we modify x_reshape:
[[1 2 3]
[4 5 6]]
x_reshape after we modify its top left element:
[[5 2 3]
[4 5 6]]
x after we modify top left element of x_reshape:
[5 2 3 4 5 6]
Notice that modifying x_reshape also changed the original array x! This is because x_reshape (in this case) is a view of x. Reshaping, in many situations, creates a view rather than a copy to save memory and improve performance.
Tuples vs. Lists (Briefly):
We encountered tuples when discussing array shapes. Tuples are similar to lists in that they are sequences of items. However, tuples are immutable, meaning you cannot modify their elements after creation. Lists, on the other hand, are mutable. Tuples are often used for representing fixed collections of items, like array shapes or function arguments.
my_tuple = (3, 4, 5)
# my_tuple[0] = 2 # This will raise an error because tuples are immutableArray Transpose:
The T attribute of a NumPy array returns its transpose. For a matrix, the transpose swaps rows and columns.
x_reshape.shape, x_reshape.ndim, x_reshape.T((2, 3),
2,
array([[5, 4],
[2, 5],
[3, 6]]))Mathematical Functions on Arrays:
NumPy provides a wide range of mathematical functions that operate element-wise on arrays.
np.sqrt(x) # Element-wise square rootarray([2.23606798, 1.41421356, 1.73205081, 2. , 2.23606798,
2.44948974])x**2 # Element-wise squaring (exponentiation)array([25, 4, 9, 16, 25, 36])Random Number Generation with NumPy:
NumPy’s random module is essential for generating random numbers in various distributions, which is crucial for simulations, statistical modeling, and machine learning.
The np.random.normal() function generates random numbers from a normal (Gaussian) distribution.
The documentation (accessed via np.random.normal?) shows the function’s signature: normal(loc=0.0, scale=1.0, size=None). loc is the mean (default 0.0), scale is the standard deviation (default 1.0), and size specifies the shape of the output array. These are keyword arguments, meaning you can specify them by name in any order.
x = np.random.normal(size=50) # 50 random numbers from standard normal N(0, 1)
xarray([-0.78698016, -0.69286162, 2.5657638 , 0.70432684, -1.35762929,
0.05290041, -0.83312708, -1.37581487, -1.6337578 , 1.36148929,
-0.02804269, 1.51823331, -1.54285248, 0.27031864, 0.60403594,
0.81083903, -0.44855606, -0.27457493, -0.08464204, -0.89499062,
-1.9268589 , -1.04291066, -1.59306156, -1.05501409, 1.85966841,
2.67424155, -0.14737829, -0.18636912, -0.30141322, 1.11890205,
1.79983329, -0.17723008, 1.3291172 , 0.74978566, 1.46739739,
0.81577834, -2.02054581, -0.70316534, -1.54396155, -0.5058598 ,
-0.16778299, 0.99880426, -1.06037769, 1.17145814, -0.75287629,
0.23467061, -0.07294178, 0.03447394, 0.36092126, -0.60327149])y = x + np.random.normal(loc=50, scale=1, size=50) # Add N(50, 1) noise to xCorrelation Coefficient:
The np.corrcoef() function calculates the correlation coefficient between two arrays.
np.corrcoef(x, y)array([[1. , 0.75216231],
[0.75216231, 1. ]])Reproducibility with Random Seeds:
Random number generators are actually pseudo-random. They produce sequences of numbers that appear random but are determined by an initial seed value. If you use the same seed, you’ll get the same sequence of “random” numbers. This is important for reproducibility in scientific computing.
To set a random seed in NumPy, you use np.random.default_rng().
rng = np.random.default_rng(1303) # Create a random number generator with seed 1303
print(rng.normal(scale=5, size=2)) # Generate random numbers using this generator
rng2 = np.random.default_rng(1303) # Create another generator with the same seed
print(rng2.normal(scale=5, size=2)) # It will produce the same random numbers[ 4.09482632 -1.07485605]
[ 4.09482632 -1.07485605]
By setting a random seed using np.random.default_rng(seed_value), you ensure that your code will produce the same random results every time you run it, making your work reproducible. We will use random seeds throughout the labs to ensure consistent results.
Descriptive Statistics: Mean, Variance, Standard Deviation:
NumPy provides functions to calculate common descriptive statistics: np.mean(), np.var(), np.std(). These are also available as methods of NumPy arrays: array.mean(), array.var(), array.std().
rng = np.random.default_rng(3)
y = rng.standard_normal(10) # 10 random numbers from standard normal
np.mean(y), y.mean() # Calculate mean using function and method(-0.1126795190952861, -0.1126795190952861)np.var(y), y.var(), np.mean((y - y.mean()) ** 2) # Calculate variance(2.7243406406465125, 2.7243406406465125, 2.7243406406465125)Note that by default, np.var() and y.var() calculate the population variance (dividing by ). To calculate the sample variance (dividing by ), you can use the ddof=1 argument (degrees of freedom = 1).
np.sqrt(np.var(y)), np.std(y) # Standard deviation is the square root of variance(1.6505576756498128, 1.6505576756498128)Mean, Variance, Standard Deviation along Axes:
For multidimensional arrays (matrices), you can calculate statistics along specific axes. axis=0 refers to columns (moving down rows), and axis=1 refers to rows (moving across columns).
X = rng.standard_normal((10, 3)) # 10x3 matrix of random normals
Xarray([[ 0.22578661, -0.35263079, -0.28128742],
[-0.66804635, -1.05515055, -0.39080098],
[ 0.48194539, -0.23855361, 0.9577587 ],
[-0.19980213, 0.02425957, 1.54582085],
[ 0.54510552, -0.50522874, -0.18283897],
[ 0.54052513, 1.93508803, -0.26962033],
[-0.24355868, 1.0023136 , -0.88645994],
[-0.29172023, 0.88253897, 0.58035002],
[ 0.0915167 , 0.67010435, -2.82816231],
[ 1.02130682, -0.95964476, -1.66861984]])X.mean(axis=0) # Mean of each column (average across rows)array([ 0.15030588, 0.14030961, -0.34238602])X.mean(0) # Shorthand for axis=0array([ 0.15030588, 0.14030961, -0.34238602])NumPy is a powerful library for numerical computing in Python. It provides efficient arrays, mathematical functions, random number generation, and tools for descriptive statistics. Mastering NumPy is essential for data science and scientific computing with Python. For more in-depth information, refer to the NumPy quickstart guide: docs
Graphics with Matplotlib¶
Visualizing data is crucial for understanding patterns, trends, and relationships. In Python, the standard library for creating plots and visualizations is Matplotlib. Specifically, we’ll use the pyplot module within Matplotlib, which provides a convenient interface for creating various types of plots.
Matplotlib is a comprehensive plotting library, offering a wide range of plot types and customization options. While Python wasn’t initially designed for data analysis, Matplotlib has become an indispensable tool for data visualization in the Python ecosystem.
Figures and Axes in Matplotlib:
In Matplotlib, a plot is structured around two main components:
- Figure: The overall window or page where your plot(s) are drawn. Think of it as the canvas. A figure can contain one or more axes.
- Axes: A specific plot within a figure. It’s the area where data is plotted. An axes includes the x-axis, y-axis, data points, labels, title, and other plot elements. (Note: “axes” is plural and refers to the entire plot area, not just the x and y axes themselves.)
Creating Figures and Axes with subplots():
We’ll use the subplots() function from matplotlib.pyplot to create figures and axes.
from matplotlib.pyplot import subplots
fig, ax = subplots(figsize=(8, 8)) # Create a figure and a single axes
subplots(figsize=(8, 8)) creates a figure and a single axes object within that figure. figsize is a keyword argument that specifies the size of the figure in inches (width, height). subplots() returns a tuple containing the figure object and the axes object. We use tuple unpacking to assign these objects to the variables fig and ax.
Line Plots and Scatter Plots:
The ax.plot() method is used to create plots on the axes object ax. By default, ax.plot() creates a line plot.
fig, ax = subplots(figsize=(8, 8))
x = rng.standard_normal(100)
y = rng.standard_normal(100)
ax.plot(x, y); # Create a line plot of y vs. x
To create a scatterplot instead of a line plot, we can pass an additional argument to ax.plot() specifying the marker style. "o" indicates circles as markers.
fig, ax = subplots(figsize=(8, 8))
ax.plot(x, y, "o"); # Create a scatter plot with circle markers
Alternatively, you can use the ax.scatter() function specifically for creating scatter plots.
fig, ax = subplots(figsize=(8, 8))
ax.scatter(x, y, marker="o"); # Create a scatter plot using ax.scatter()Suppressing Output with Semicolons:
In Jupyter notebooks, the output of the last line of a cell is automatically displayed. Sometimes, you might not want to display text output from plotting commands (e.g., long lines of Matplotlib output). You can suppress this text output by ending the line with a semicolon ;. The semicolon does not prevent the plot from being displayed, it only suppresses text output.
fig, ax = subplots(figsize=(8, 8))
ax.scatter(
x,
y,
marker="o",
); # Semicolon suppresses text output, but plot is still shownPlot Labels and Titles:
To make plots informative, you should add labels to the axes and a title to the plot. You can use the ax.set_xlabel(), ax.set_ylabel(), and ax.set_title() methods for this.
fig, ax = subplots(figsize=(8, 8))
ax.scatter(x, y, marker="o")
ax.set_xlabel("this is the x-axis")
ax.set_ylabel("this is the y-axis")
ax.set_title("Plot of X vs Y");
Modifying Figure Size:
You can change the size of an existing figure using the fig.set_size_inches() method.
fig.set_size_inches(12, 3) # Change figure size to 12 inches wide, 3 inches tall
fig # Re-display the modified figure
Multiple Plots in a Figure (Subplots):
You can create figures with multiple plots arranged in a grid using subplots(). The nrows and ncols keyword arguments specify the number of rows and columns of subplots.
fig, axes = subplots(nrows=2, ncols=3, figsize=(15, 5)) # 2 rows, 3 columns of subplots
subplots(nrows=2, ncols=3) returns a figure object fig and an array of axes objects axes. axes is a 2x3 NumPy array where each element axes[i, j] corresponds to the axes object for the subplot in the i-th row and j-th column.
axes[0, 1].plot(x, y, "o") # Scatter plot in the subplot at row 0, column 1
axes[1, 2].scatter(x, y, marker="+") # Scatter plot with '+' markers in row 1, column 2
fig # Display the figure with subplots
Saving Figures:
You can save figures to image files using the fig.savefig() method.
fig.savefig("Figure.png", dpi=400) # Save as PNG, 400 dots per inch
fig.savefig("Figure.pdf", dpi=200); # Save as PDF, 200 dots per inchfig.savefig() takes the filename as the first argument. The dpi argument controls the resolution of the saved image (dots per inch). Higher DPI values result in higher resolution images.
Contour Plots:
Contour plots are used to visualize three-dimensional data in two dimensions. They represent surfaces by drawing contour lines (lines of constant value) on a 2D plane. ax.contour() creates contour plots. It typically takes three arguments: x-coordinates, y-coordinates, and a 2D array representing the z-values (heights) at each (x, y) point.
fig, ax = subplots(figsize=(8, 8))
x = np.linspace(-np.pi, np.pi, 50) # Create 50 points from -pi to pi
y = x
f = np.multiply.outer(
np.cos(y),
1 / (1 + x**2),
) # Calculate z-values (function of x and y)
ax.contour(x, y, f); # Create contour plot
np.linspace(a, b, n) creates an array of n evenly spaced numbers from a to b. np.multiply.outer() calculates the outer product of two arrays.
fig, ax = subplots(figsize=(8, 8))
ax.contour(x, y, f, levels=45); # Increase contour resolution by adding more levels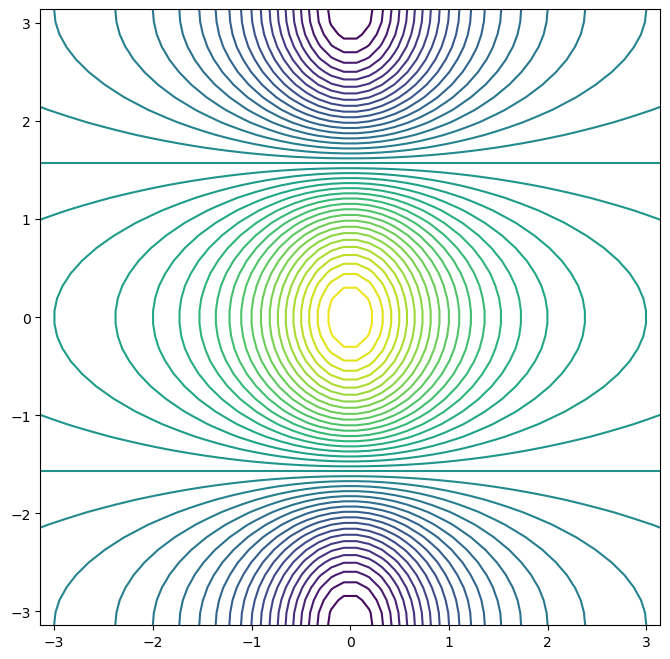
The levels argument controls the number of contour lines to be drawn.
Heatmaps (Image Plots):
Heatmaps or image plots represent data as a color-coded grid. ax.imshow() creates heatmaps. It takes a 2D array as input, and the color of each cell in the grid is determined by the corresponding value in the array.
fig, ax = subplots(figsize=(8, 8))
ax.imshow(f); # Create a heatmap from the 2D array f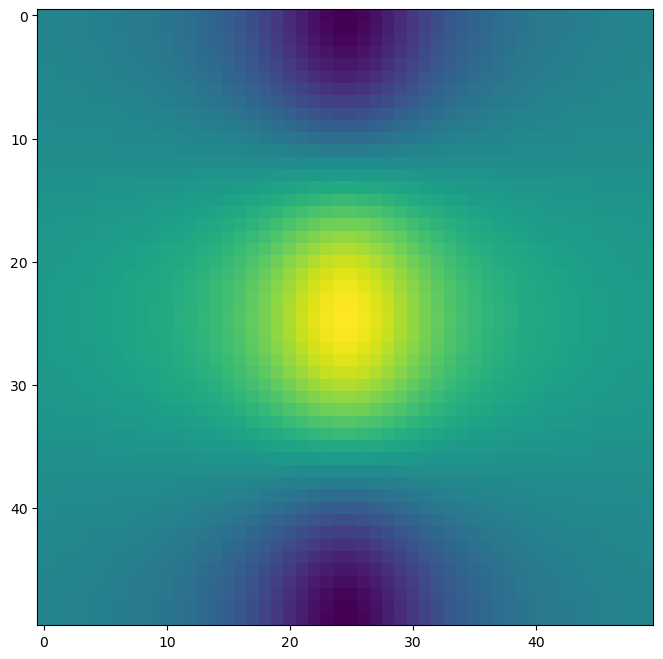
Matplotlib is a vast library with extensive capabilities for creating various types of plots and customizing their appearance. For more examples and options, explore the Matplotlib gallery: matplotlib
Sequences and Slice Notation¶
Python and NumPy extensively use the concept of sequences to represent ordered collections of data. We’ve already encountered lists and tuples as Python sequences, and NumPy arrays are also sequences. Slice notation is a powerful and concise way to access subsets or ranges of elements within sequences.
Creating Sequences:
NumPy provides functions to create numerical sequences easily.
np.linspace(start, stop, num) creates a sequence of num evenly spaced numbers between start and stop (inclusive).
seq1 = np.linspace(0, 10, 11) # 11 numbers from 0 to 10, evenly spaced
seq1array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])np.arange(start, stop, step) creates a sequence of numbers starting from start, incrementing by step, and stopping before reaching stop (exclusive of stop). If step is not specified, it defaults to 1.
seq2 = np.arange(0, 10) # Numbers from 0 to 9 (step=1 by default)
seq2array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])Slice Notation: Accessing Subsequences:
Slice notation uses square brackets [] and colons : to specify a range of indices. The general format is [start:stop:step].
start: The starting index (inclusive, default is 0).stop: The ending index (exclusive).step: The step size or increment (default is 1).
"hello world"[3:6] # Slice of a string from index 3 to 5 (exclusive of 6)'lo 'In this example, [3:6] is a slice object (internally, it’s slice(3, 6)). It extracts characters from index 3 up to (but not including) index 6.
"hello world"[slice(3, 6)] # Equivalent to the above using slice object explicitly'lo 'Understanding Slice Endpoints:
A key thing to remember about slice notation is that the stop index is exclusive. This is why np.arange(0, 10) produces numbers from 0 to 9, not including 10. Similarly, slice(3, 6) extracts elements at indices 3, 4, and 5, but not 6.
Slice Defaults:
If you omit start, it defaults to 0 (beginning of the sequence). If you omit stop, it defaults to the end of the sequence. If you omit step, it defaults to 1.
my_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
my_list[:5] # From beginning up to index 5 (exclusive)
my_list[5:] # From index 5 to the end
my_list[::2] # Every other element (step=2)
my_list[::-1] # Reverse the sequence (step=-1)[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]Slice notation is extremely versatile and is used extensively in Python and NumPy for accessing and manipulating parts of sequences. For more options and details on slice objects, see the documentation: slice?.
Indexing Data: Accessing Elements in Arrays and DataFrames¶
Indexing is the process of selecting specific elements or subsets of data from arrays, matrices, and data frames. We’ve already seen basic indexing with NumPy arrays. Let’s explore more advanced indexing techniques.
Creating a Sample Array:
Let’s create a 4x4 NumPy array to demonstrate indexing:
A = np.array(np.arange(16)).reshape((4, 4)) # Create a 4x4 array with values 0-15
Aarray([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])Basic Indexing: Single Element Access:
To access a single element in a 2D array A, use A[row_index, column_index]. Remember that indexing is zero-based.
A[1, 2] # Element at row index 1 (2nd row), column index 2 (3rd column)6Indexing Rows, Columns, and Submatrices:
Selecting Multiple Rows or Columns using Lists:
To select multiple rows, pass a list of row indices as the first index. To select all columns, use a colon : as the second index.
A[[1, 3]] # Select rows at index 1 and 3 (2nd and 4th rows), all columnsarray([[ 4, 5, 6, 7],
[12, 13, 14, 15]])To select specific columns, pass a list of column indices as the second index and use : to select all rows.
A[:, [0, 2]] # Select all rows, columns at index 0 and 2 (1st and 3rd columns)array([[ 0, 2],
[ 4, 6],
[ 8, 10],
[12, 14]])Attempting to Select Submatrices Incorrectly:
A common mistake when trying to select a submatrix is to use two lists of indices directly:
A[[1, 3], [0, 2]] # Incorrect way to select a submatrixarray([ 4, 14])This does not select the submatrix formed by rows 1 and 3 and columns 0 and 2. Instead, it performs element-wise indexing, returning a 1D array: [A[1,0], A[3,2]].
Correctly Selecting Submatrices:
To select a submatrix (a rectangular portion of the array), you need to use a combination of indexing techniques. One way is to chain indexing operations:
A[[1, 3]][
:,
[0, 2],
] # Select rows 1 and 3 first, then from that result, select columns 0 and 2array([[ 4, 6],
[12, 14]])This first selects rows 1 and 3, creating an intermediate array. Then, from this intermediate array, it selects columns 0 and 2, resulting in the desired submatrix.
Using np.ix_() for Submatrix Selection:
NumPy’s np.ix_() function provides a more convenient and efficient way to select submatrices using lists of row and column indices. np.ix_() creates an “index mesh” that allows for proper submatrix indexing.
idx = np.ix_(
[1, 3],
[0, 2, 3],
) # Create index mesh for rows [1, 3] and columns [0, 2, 3]
A[idx] # Use the index mesh to select the submatrixarray([[ 4, 6, 7],
[12, 14, 15]])Submatrix Selection using Slices:
Slices are a very efficient way to select contiguous submatrices.
A[1:4:2, 0:3:2] # Select rows from index 1 to 3 (step 2), columns from 0 to 2 (step 2)array([[ 4, 6],
[12, 14]])1:4:2 selects rows with indices 1 and 3 (start=1, stop=4, step=2). 0:3:2 selects columns with indices 0 and 2.
Why Slices Work for Submatrices, but Lists Don’t Directly:
Slices and lists are treated differently by NumPy indexing. Slices are designed for selecting contiguous ranges, making them naturally suited for submatrix selection. Lists, when used directly in multidimensional indexing (like A[[1,3],[0,2]]), are interpreted as index pairs for element-wise selection, not submatrix selection. np.ix_() bridges this gap by creating an index mesh that allows lists to be used for submatrix selection.
Boolean Indexing:
Boolean indexing is a powerful technique for selecting elements based on conditions. You create a Boolean array (an array of True and False values) and use it to index another array. Elements corresponding to True in the Boolean array are selected.
keep_rows = np.zeros(
A.shape[0],
bool,
) # Create a Boolean array of False with length equal to number of rows in A
keep_rowsarray([False, False, False, False])keep_rows[[1, 3]] = True # Set elements at index 1 and 3 to True
keep_rowsarray([False, True, False, True])Now, keep_rows is a Boolean array: [False, True, False, True]. When used to index A, it selects the rows where keep_rows is True.
A[keep_rows] # Select rows where keep_rows is True (rows 1 and 3)array([[ 4, 5, 6, 7],
[12, 13, 14, 15]])Boolean Indexing vs. Integer Indexing:
It’s important to distinguish between Boolean indexing and integer indexing. Even though np.array([0,1,0,1]) and keep_rows might seem numerically similar (if you treat True as 1 and False as 0), they behave differently in indexing.
A[
np.array([0, 1, 0, 1])
] # Integer indexing: select rows at indices 0, 1, 0, 1 (repeats rows)array([[0, 1, 2, 3],
[4, 5, 6, 7],
[0, 1, 2, 3],
[4, 5, 6, 7]])Integer indexing with [0, 1, 0, 1] selects and repeats rows based on the integer indices. Boolean indexing with keep_rows selects rows where the corresponding Boolean value is True.
Boolean Indexing with np.ix_():
You can combine Boolean indexing with np.ix_() to select submatrices based on Boolean conditions for both rows and columns.
keep_cols = np.zeros(A.shape[1], bool) # Boolean array for columns
keep_cols[[0, 2, 3]] = True # Select columns 0, 2, 3
idx_bool = np.ix_(keep_rows, keep_cols) # Create Boolean index mesh
A[idx_bool] # Select submatrix based on Boolean row and column conditionsarray([[ 4, 6, 7],
[12, 14, 15]])Mixing Lists and Boolean Arrays with np.ix_():
np.ix_() is flexible and allows you to mix lists of indices with Boolean arrays for submatrix selection.
idx_mixed = np.ix_(
[1, 3],
keep_cols,
) # Mix list of row indices with Boolean column array
A[idx_mixed]array([[ 4, 6, 7],
[12, 14, 15]])NumPy’s indexing capabilities, including integer indexing, slice notation, Boolean indexing, and np.ix_(), provide powerful and versatile ways to access and manipulate data within arrays and matrices. Understanding these techniques is essential for efficient data analysis and manipulation in Python. For a comprehensive guide to NumPy indexing, refer to the NumPy tutorial.
Loading Data with Pandas¶
In data analysis, you often work with datasets stored in external files. Pandas is a powerful Python library specifically designed for data manipulation and analysis. It introduces the DataFrame, a tabular data structure that is highly effective for working with structured data.
DataFrames: Tabular Data in Pandas:
A Pandas DataFrame is like a table or a spreadsheet. It organizes data into rows and columns. Each column can have a different data type (numeric, string, datetime, etc.). DataFrames also have row and column labels (indices and column names), making it easy to access and manipulate data.
Reading Data from Files:
Pandas provides functions to read data from various file formats. pd.read_csv() is used to read data from CSV (Comma-Separated Values) files, which are a common format for storing tabular data.
import pandas as pd # Import pandas library
Auto = pd.read_csv("../Auto.csv") # Read data from "Auto.csv" into a DataFrame
Auto # Display the DataFramepd.read_csv("Auto.csv") reads the data from the file “Auto.csv” (assuming it’s in the same directory as your notebook) and creates a DataFrame named Auto. Running Auto displays the DataFrame in a tabular format.
Reading Whitespace-Delimited Data:
Some data files use whitespace (spaces, tabs) as delimiters instead of commas. For these files, you can use pd.read_csv() with the delim_whitespace=True argument.
Auto = pd.read_csv(
"../Auto.data",
delim_whitespace=True,
) # Read whitespace-delimited data/tmp/ipykernel_76161/1410907731.py:1: FutureWarning: The 'delim_whitespace' keyword in pd.read_csv is deprecated and will be removed in a future version. Use ``sep='\s+'`` instead
Auto = pd.read_csv("../Auto.data", delim_whitespace=True) # Read whitespace-delimited data
Handling Missing Values:
Data files often contain missing values, which are represented in various ways (e.g., NA, ?, blank spaces). When reading data, Pandas can automatically handle certain missing value representations. However, you might need to specify custom missing value indicators using the na_values argument in pd.read_csv().
Let’s examine the “horsepower” column in our Auto DataFrame:
Auto["horsepower"] # Access the "horsepower" column0 130.0
1 165.0
2 150.0
3 150.0
4 140.0
...
392 86.00
393 52.00
394 84.00
395 79.00
396 82.00
Name: horsepower, Length: 397, dtype: objectThe dtype of this column is object, which indicates that Pandas has interpreted the “horsepower” values as strings (text), not numbers. This is likely because there are non-numeric values in the column.
Let’s find the unique values in the “horsepower” column:
np.unique(Auto["horsepower"]) # Find unique values in "horsepower" columnarray(['100.0', '102.0', '103.0', '105.0', '107.0', '108.0', '110.0',
'112.0', '113.0', '115.0', '116.0', '120.0', '122.0', '125.0',
'129.0', '130.0', '132.0', '133.0', '135.0', '137.0', '138.0',
'139.0', '140.0', '142.0', '145.0', '148.0', '149.0', '150.0',
'152.0', '153.0', '155.0', '158.0', '160.0', '165.0', '167.0',
'170.0', '175.0', '180.0', '190.0', '193.0', '198.0', '200.0',
'208.0', '210.0', '215.0', '220.0', '225.0', '230.0', '46.00',
'48.00', '49.00', '52.00', '53.00', '54.00', '58.00', '60.00',
'61.00', '62.00', '63.00', '64.00', '65.00', '66.00', '67.00',
'68.00', '69.00', '70.00', '71.00', '72.00', '74.00', '75.00',
'76.00', '77.00', '78.00', '79.00', '80.00', '81.00', '82.00',
'83.00', '84.00', '85.00', '86.00', '87.00', '88.00', '89.00',
'90.00', '91.00', '92.00', '93.00', '94.00', '95.00', '96.00',
'97.00', '98.00', '?'], dtype=object)We see the value '?' in the unique values. It appears that '?' is used to represent missing values in the “horsepower” column. Pandas, by default, doesn’t recognize '?' as a missing value indicator.
To correctly handle '?' as missing values, we can use the na_values argument in pd.read_csv(). We tell Pandas to treat '?' as missing values, and Pandas will replace them with NaN (Not a Number), which is Pandas’ standard representation for missing values.
Auto = pd.read_csv(
"../Auto.data",
na_values=["?"], # Treat "?" as missing values
delim_whitespace=True,
)
Auto["horsepower"].sum() # Try to sum "horsepower" column/tmp/ipykernel_76161/4036388500.py:1: FutureWarning: The 'delim_whitespace' keyword in pd.read_csv is deprecated and will be removed in a future version. Use ``sep='\s+'`` instead
Auto = pd.read_csv("../Auto.data",
40952.0After specifying na_values=["?"], Pandas correctly reads '?' as missing values (NaN). Attempting to sum the “horsepower” column now might result in NaN because of the missing values.
DataFrame Shape:
The Auto.shape attribute of a DataFrame returns a tuple indicating the number of rows and columns: (rows, columns).
Auto.shape # Get the shape of the DataFrame(397, 9)Handling Missing Data: Dropping Rows with Missing Values:
Pandas provides various ways to handle missing data. One simple approach is to remove rows that contain missing values using the dropna() method.
Auto_new = Auto.dropna() # Create a new DataFrame with rows containing NaN removed
Auto_new.shape # Check the shape of the new DataFrame(392, 9)Auto.dropna() creates a new DataFrame Auto_new where rows with any NaN values are removed. The shape of Auto_new will be smaller than Auto if rows were dropped.
Auto = Auto_new # Overwrite the original DataFrame with the DataFrame without missing valuesIt’s common to overwrite the original DataFrame variable with the cleaned DataFrame after handling missing values.
DataFrame Columns:
The Auto.columns attribute gives you a list of column names in the DataFrame.
Auto.columns # Get the column names of the DataFrameIndex(['mpg', 'cylinders', 'displacement', 'horsepower', 'weight',
'acceleration', 'year', 'origin', 'name'],
dtype='object')Pandas DataFrames are powerful tools for reading, cleaning, and manipulating tabular data. They provide efficient ways to handle missing values, select subsets of data, perform calculations, and much more. In the following sections, we’ll explore more DataFrame operations for data analysis.
Basics of Selecting Rows and Columns in DataFrames¶
Pandas DataFrames offer flexible ways to select and access rows and columns of data. Understanding these selection methods is crucial for data manipulation and analysis.
Accessing Columns:
You can access a single column of a DataFrame using square bracket notation [] with the column name as a string.
Auto["horsepower"] # Access the "horsepower" column as a Pandas Series0 130.0
1 165.0
2 150.0
3 150.0
4 140.0
...
392 86.0
393 52.0
394 84.0
395 79.0
396 82.0
Name: horsepower, Length: 392, dtype: float64This returns a Pandas Series, which is a one-dimensional labeled array representing a single column of the DataFrame.
To access multiple columns, pass a list of column names within the square brackets.
Auto[["mpg", "horsepower"]] # Access "mpg" and "horsepower" columns as a DataFrameThis returns a new DataFrame containing only the specified columns.
Accessing Rows using Slices:
Similar to NumPy arrays and Python lists, you can use slice notation to select a range of rows from a DataFrame. When you use slice notation directly with a DataFrame (like Auto[:3]), it operates on the rows.
Auto[:3] # Select the first 3 rows of the DataFrameThis returns a DataFrame containing the first three rows (rows with index 0, 1, and 2).
Accessing Rows using Boolean Indexing:
You can use a Boolean Series (a Series of True and False values) to select rows based on conditions.
idx_80 = Auto["year"] > 80 # Create a Boolean Series: True for cars built after 1980
Auto[idx_80] # Select rows where idx_80 is True (cars built after 1980)This selects rows where the condition Auto["year"] > 80 is True.
DataFrame Index:
DataFrames have an index, which labels the rows. If you don’t explicitly set an index when reading data, Pandas automatically creates a default integer index starting from 0.
Auto.index # Get the index of the DataFrameIndex([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
...
387, 388, 389, 390, 391, 392, 393, 394, 395, 396],
dtype='int64', length=392)Setting DataFrame Index:
You can set a column of the DataFrame as the index using the set_index() method. This can be useful if you have a column with unique identifiers for each row (e.g., car names).
Auto_re = Auto.set_index("name") # Set the "name" column as the index
Auto_re # Display the DataFrame with the new indexAuto.set_index("name") creates a new DataFrame Auto_re where the “name” column is now the index, and the “name” column itself is removed as a regular column.
Auto_re.columns # Check the columns of the DataFrame after setting indexIndex(['mpg', 'cylinders', 'displacement', 'horsepower', 'weight',
'acceleration', 'year', 'origin'],
dtype='object')Accessing Rows by Index Labels using .loc[]:
After setting an index, you can access rows using their index labels with the .loc[] indexer.
rows = ["amc rebel sst", "ford torino"] # List of index labels (car names)
Auto_re.loc[rows] # Select rows with index labels in the 'rows' listAuto_re.loc[rows] selects rows whose index labels are in the rows list.
Accessing Rows and Columns by Integer Position using .iloc[]:
The .iloc[] indexer allows you to access rows and columns based on their integer positions (0-based indices), regardless of the index labels.
Auto_re.iloc[[3, 4]] # Select rows at integer position 3 and 4 (4th and 5th rows)Auto_re.iloc[
:,
[0, 2, 3],
] # Select all rows, columns at integer position 0, 2, 3 (1st, 3rd, 4th columns)Auto_re.iloc[
[3, 4],
[0, 2, 3],
] # Select rows at position 3 and 4, columns at position 0, 2, 3.loc[] vs. .iloc[]:
.loc[]: Primarily for label-based indexing. Use index labels (row names, column names) to select data..iloc[]: Primarily for integer-position-based indexing. Use integer positions (0, 1, 2, ...) to select data, regardless of labels.
Duplicate Index Entries:
DataFrame indices don’t have to be unique. There can be multiple rows with the same index label.
Auto_re.loc[
"ford galaxie 500",
["mpg", "origin"],
] # Select rows with index "ford galaxie 500"If there are multiple rows with the same index label, .loc[] will return all of them.
More on Selecting Rows and Columns with Pandas¶
Let’s delve deeper into advanced row and column selection techniques in Pandas DataFrames.
Combining Boolean Indexing and Column Selection:
Suppose we want to select specific columns (weight and origin) for a subset of cars (those built after 1980). We can combine Boolean indexing for rows and column selection using .loc[].
idx_80 = Auto_re["year"] > 80 # Boolean Series for cars after 1980
Auto_re.loc[
idx_80,
["weight", "origin"],
] # Select rows where idx_80 is True, and columns "weight", "origin"Functional Row Selection with lambda Functions and .loc[]:
Pandas .loc[] indexer can accept functions (often lambda functions) as row or column selectors. Lambda functions are small, anonymous functions defined inline. They are useful for creating concise functions for filtering or transforming data.
Auto_re.loc[
lambda df: df["year"] > 80,
["weight", "origin"],
] # Functional row selection using lambdalambda df: df["year"] > 80 defines an anonymous function that takes a DataFrame df as input and returns a Boolean Series df["year"] > 80. .loc[] then uses this Boolean Series to select rows from Auto_re.
Combining Multiple Conditions with & (and) and | (or):
You can combine multiple conditions in Boolean indexing using the & (and) and | (or) operators. Remember to enclose each condition in parentheses () for correct operator precedence.
Auto_re.loc[
lambda df: (df["year"] > 80) & (df["mpg"] > 30), # Cars after 1980 AND mpg > 30
["weight", "origin"],
]String-Based Filtering with .str.contains():
For DataFrames with string indices or columns, you can use string methods like .str.contains() for filtering based on string patterns.
Suppose we want to select “Ford” and “Datsun” cars with displacement less than 300. We can use .str.contains() on the DataFrame index (which is “name” in Auto_re) to check if the car name contains “ford” or “datsun”.
Auto_re.loc[
lambda df: (df["displacement"] < 300)
& (
df.index.str.contains("ford") # Check if index (car name) contains "ford"
| df.index.str.contains("datsun")
), # OR contains "datsun"
["weight", "origin"],
]df.index.str.contains("ford") applies the string method .contains("ford") to each element of the DataFrame index (car names). It returns a Boolean Series indicating whether each index label contains “ford”. Similarly for df.index.str.contains("datsun"). We use | (or) to combine these conditions.
Summary of DataFrame Indexing:
Pandas DataFrames offer a rich set of indexing methods for selecting rows and columns:
- Column Selection:
DataFrame["column_name"],DataFrame[["col1", "col2"]] - Row Selection (Slices):
DataFrame[start_row:end_row] - Row Selection (Boolean Indexing):
DataFrame[Boolean_Series] - Label-based Indexing (
.loc[]):DataFrame.loc[row_labels, column_labels] - Integer-position-based Indexing (
.iloc[]):DataFrame.iloc[row_positions, column_positions] - Functional Row/Column Selection (
.loc[]with lambda functions):DataFrame.loc[lambda df: condition, column_selectors] - Combining Conditions (
&,|) - String-based Filtering (
.str.contains(), etc.)
Mastering these indexing techniques is essential for effectively working with and analyzing data using Pandas DataFrames.
For Loops: Repeating Operations¶
For loops are fundamental control flow structures in programming. They allow you to repeatedly execute a block of code for each item in a sequence (like a list, tuple, string, or range). For loops are essential for automating repetitive tasks and processing collections of data.
Basic For Loop Structure:
The basic syntax of a for loop in Python is:
for variable in sequence:
# Code to be executed repeatedly for each item in the sequence
# Indented block of code is the loop body
pass---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[99], line 1
----> 1 for variable in sequence:
2 # Code to be executed repeatedly for each item in the sequence
3 # Indented block of code is the loop body
4 pass
NameError: name 'sequence' is not definedThe for loop iterates through each item in the sequence. In each iteration, the variable is assigned the current item, and the code inside the indented block (the loop body) is executed.
Example: Summing List Elements:
total = 0
for value in [3, 2, 19]: # Iterate through the list [3, 2, 19]
total += value # Add each value to the total
print(f"Total is: {total}") # Print the final totalTotal is: 24
In this loop:
totalis initialized to 0.- The loop iterates through the list
[3, 2, 19]. - In the first iteration,
valueis assigned 3, andtotalbecomes0 + 3 = 3. - In the second iteration,
valueis assigned 2, andtotalbecomes3 + 2 = 5. - In the third iteration,
valueis assigned 19, andtotalbecomes5 + 19 = 24. - After the loop finishes, the final value of
total(24) is printed.
Nested For Loops:
You can nest for loops inside each other to iterate over multiple sequences.
total = 0
for value in [2, 3, 19]: # Outer loop iterates through [2, 3, 19]
for weight in [3, 2, 1]: # Inner loop iterates through [3, 2, 1] for each value
total += value * weight # Calculate value * weight and add to total
print(f"Total is: {total}")Total is: 144
In this nested loop, the inner loop runs completely for each iteration of the outer loop. For each value in [2, 3, 19], the inner loop iterates through all weight values in [3, 2, 1].
Increment Notation (+=, -=, *=, /=):
Python provides shorthand increment operators like +=, -=, *=, /=. a += b is equivalent to a = a + b. These operators are often more concise and can be slightly more efficient in some cases.
Using zip() to Iterate over Multiple Sequences Simultaneously:
The zip() function is useful for iterating over multiple sequences in parallel. It combines corresponding elements from multiple sequences into tuples.
total = 0
for value, weight in zip(
[2, 3, 19], # Zip together values and weights lists
[0.2, 0.3, 0.5],
):
total += weight * value # Calculate weighted sum
print(f"Weighted average is: {total}")Weighted average is: 10.8
zip([2, 3, 19], [0.2, 0.3, 0.5]) creates an iterator that yields tuples: (2, 0.2), (3, 0.3), (19, 0.5). The for loop unpacks each tuple into value and weight variables in each iteration.
String Formatting: Creating Dynamic Strings:
String formatting is used to create strings dynamically by inserting values of variables into strings. Python offers several string formatting methods. One common method is using f-strings (formatted string literals), introduced in Python 3.6.
f-strings:
f-strings are created by prefixing a string literal with f or F. You can embed expressions inside f-strings by enclosing them in curly braces {}. The expressions are evaluated, and their values are inserted into the string.
name = "Alice"
age = 30
message = f"My name is {name} and I am {age} years old." # f-string for formatting
print(message)My name is Alice and I am 30 years old.
.format() method:
Another string formatting method is using the .format() method of strings. You use placeholders {} within the string and pass the values to be inserted as arguments to .format(). Placeholders can be numbered (e.g., {0}, {1}) to refer to arguments by position.
column_name = "mpg"
missing_percent = 0.05
template = (
'Column "{0}" has {1:.2%} missing values' # String template with placeholders
)
formatted_string = template.format(column_name, missing_percent) # Format the string
print(formatted_string)Column "mpg" has 5.00% missing values
{0} refers to the first argument passed to .format() (column_name), and {1:.2%} refers to the second argument (missing_percent) formatted as a percentage with 2 decimal places.
Example: Looping through DataFrame Columns and Printing Missing Percentages:
Let’s create a DataFrame with some missing values and loop through its columns to print the percentage of missing values in each column.
rng = np.random.default_rng(1)
A = rng.standard_normal((127, 5))
M = rng.choice([0, np.nan], p=[0.8, 0.2], size=A.shape)
A += M
D = pd.DataFrame(A, columns=["food", "bar", "pickle", "snack", "popcorn"])
D[:3]for col in D.columns: # Loop through column names of DataFrame D
template = 'Column "{0}" has {1:.2%} missing values' # String template for output
print(
template.format(
col, # Column name
np.isnan(D[col]).mean(),
),
) # Percentage of missing values in the columnColumn "food" has 16.54% missing values
Column "bar" has 25.98% missing values
Column "pickle" has 29.13% missing values
Column "snack" has 21.26% missing values
Column "popcorn" has 22.83% missing values
In this loop:
D.columnsgives a list of column names in DataFrameD.- The loop iterates through each
col(column name). np.isnan(D[col])checks forNaN(missing values) in the columnD[col]and returns a Boolean Series (True for NaN, False otherwise)..mean()on the Boolean Series calculates the proportion ofTruevalues (which is the fraction of missing values).template.format(col, np.isnan(D[col]).mean())formats the string using the column name and the calculated missing percentage.print()displays the formatted string for each column.
For loops and string formatting are essential tools in Python for automating tasks, processing data, and generating informative output. For more advanced string formatting options, refer to the Python string formatting documentation: docs
Additional Graphical and Numerical Summaries with Pandas¶
Pandas integrates well with Matplotlib, providing convenient methods for creating plots directly from DataFrames. Pandas also offers built-in methods for generating numerical summaries of data.
Plotting DataFrames Directly:
Pandas DataFrames have .plot attribute, which provides access to various plotting methods. You can create plots directly from DataFrame columns using these methods.
Scatter Plots with DataFrame.plot.scatter():
The DataFrame.plot.scatter(x, y) method creates a scatter plot with the column specified by x on the x-axis and the column specified by y on the y-axis.
fig, ax = subplots(figsize=(8, 8))
# ax.plot(horsepower, mpg, "o"); # This would cause an error: 'horsepower' and 'mpg' are not defined in the global scope
fig, ax = subplots(figsize=(8, 8))
ax.plot(Auto["horsepower"], Auto["mpg"], "o"); # Access columns directly from DataFrame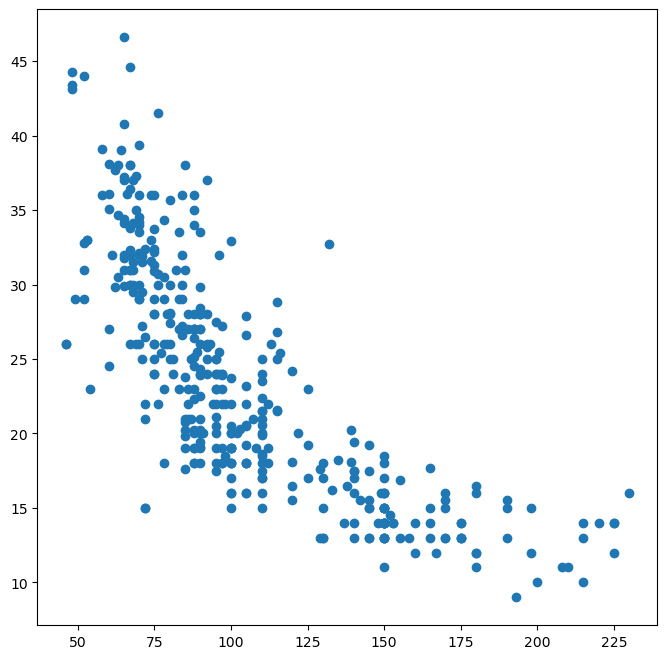
To plot DataFrame columns directly by name, you can use Auto.plot.scatter():
ax = Auto.plot.scatter(
"horsepower",
"mpg",
) # Create scatter plot using DataFrame.plot.scatter()
ax.set_title("Horsepower vs. MPG"); # Set plot title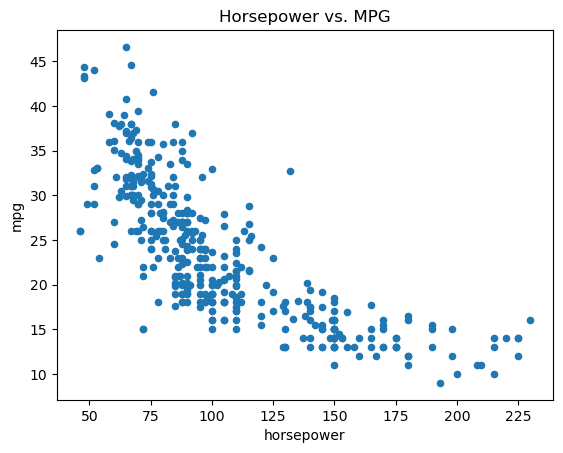
Auto.plot.scatter("horsepower", "mpg") creates a scatter plot of “mpg” vs. “horsepower” from the Auto DataFrame. It returns the Matplotlib axes object (ax), which you can then use to customize the plot further (e.g., set title, labels).
Accessing Figure from Axes:
If you have an axes object ax and want to save the entire figure containing it, you can access the figure object using ax.figure.
fig = ax.figure # Get the figure object from the axes object
fig.savefig("horsepower_mpg.png"); # Save the figurePlotting to a Specific Axes:
You can instruct Pandas plotting methods to draw on a specific Matplotlib axes object using the ax= argument. This is useful when you want to place plots within a grid of subplots.
fig, axes = subplots(
ncols=3,
figsize=(15, 5),
) # Create a figure with 3 subplots in a row
Auto.plot.scatter(
"horsepower",
"mpg",
ax=axes[1],
); # Plot scatter plot in the middle subplot (axes[1])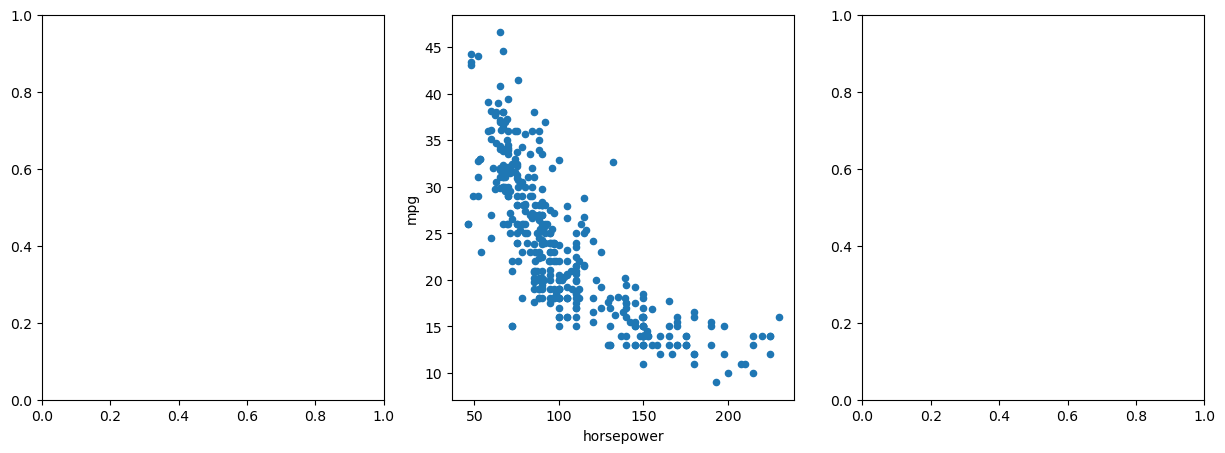
Accessing DataFrame Columns as Attributes:
You can access DataFrame columns not only using square bracket notation (Auto["horsepower"]) but also as attributes using dot notation (Auto.horsepower).
Auto.horsepower # Access "horsepower" column as an attribute0 130.0
1 165.0
2 150.0
3 150.0
4 140.0
...
392 86.0
393 52.0
394 84.0
395 79.0
396 82.0
Name: horsepower, Length: 392, dtype: float64Treating Categorical Variables: astype('category'):
Sometimes, numerical columns represent categorical variables (e.g., “cylinders” in the Auto dataset). You might want to treat them as categorical for certain analyses or visualizations. You can convert a column to categorical type using astype('category') or pd.Series(column, dtype="category").
Auto.cylinders = pd.Series(
Auto.cylinders,
dtype="category",
) # Convert "cylinders" column to category type
Auto.cylinders.dtype # Check the data type of the columnCategoricalDtype(categories=[3, 4, 5, 6, 8], ordered=False, categories_dtype=int64)Box Plots with DataFrame.boxplot():
Box plots are useful for visualizing the distribution of a numerical variable for different categories. DataFrame.boxplot(column, by) creates box plots of the column variable, grouped by the categories in the by column.
fig, ax = subplots(figsize=(8, 8))
Auto.boxplot(
"mpg",
by="cylinders",
ax=ax,
); # Create box plots of "mpg" grouped by "cylinders"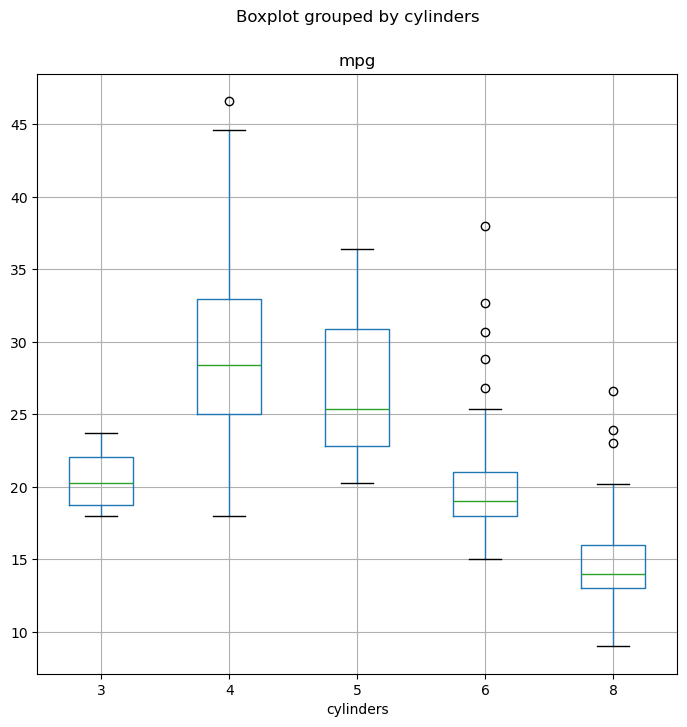
Histograms with DataFrame.hist():
Histograms visualize the distribution of a numerical variable by dividing the data into bins and showing the frequency of data points in each bin. DataFrame.hist(column) creates a histogram of the column variable.
fig, ax = subplots(figsize=(8, 8))
Auto.hist("mpg", ax=ax); # Create histogram of "mpg" column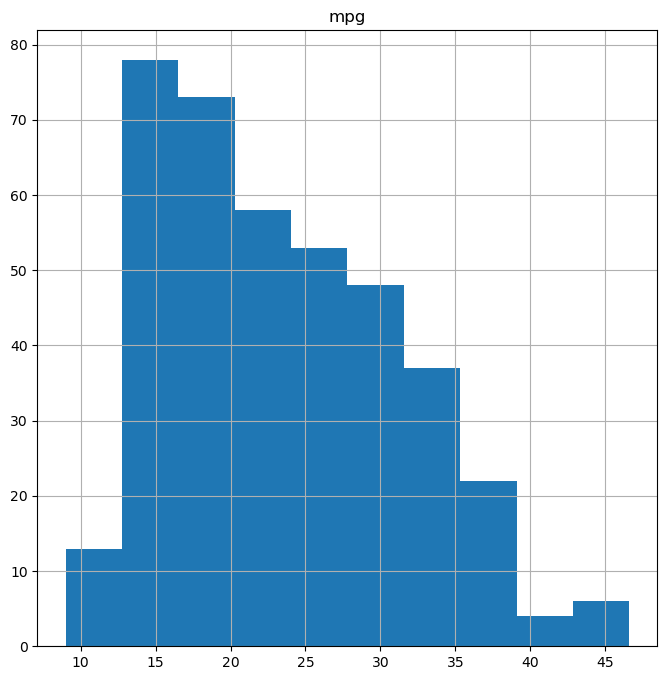
You can customize histograms using arguments like color and bins.
fig, ax = subplots(figsize=(8, 8))
Auto.hist("mpg", color="red", bins=12, ax=ax); # Histogram with red bars and 12 bins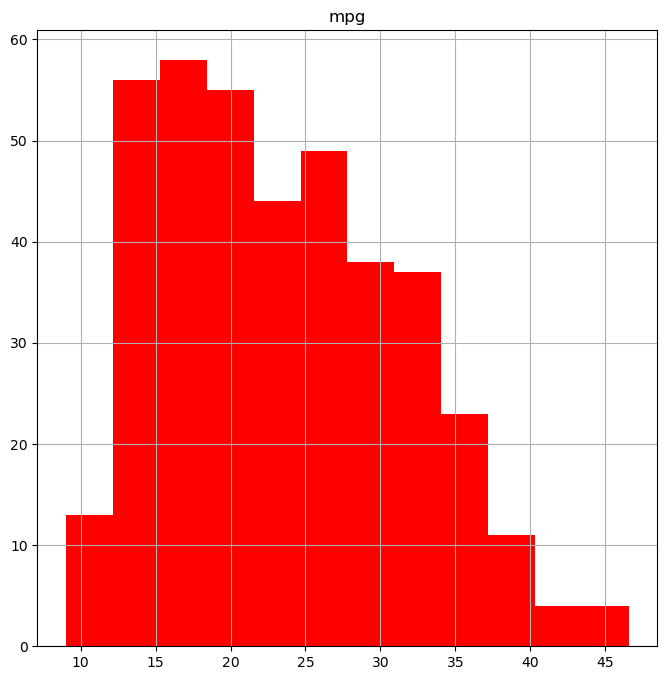
Scatterplot Matrices with pd.plotting.scatter_matrix():
Scatterplot matrices are useful for visualizing pairwise relationships between multiple variables. pd.plotting.scatter_matrix(DataFrame) creates a matrix of scatter plots for all pairs of numerical columns in the DataFrame.
pd.plotting.scatter_matrix(
Auto,
); # Create scatterplot matrix for all columns in Auto DataFrame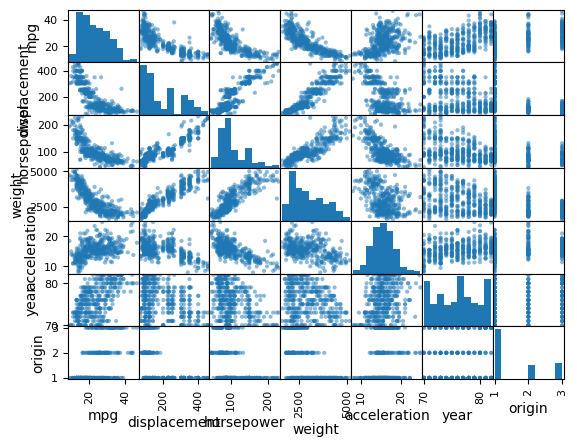
You can create scatterplot matrices for a subset of columns by passing a list of column names.
pd.plotting.scatter_matrix(
Auto[["mpg", "displacement", "weight"]],
); # Scatterplot matrix for specific columns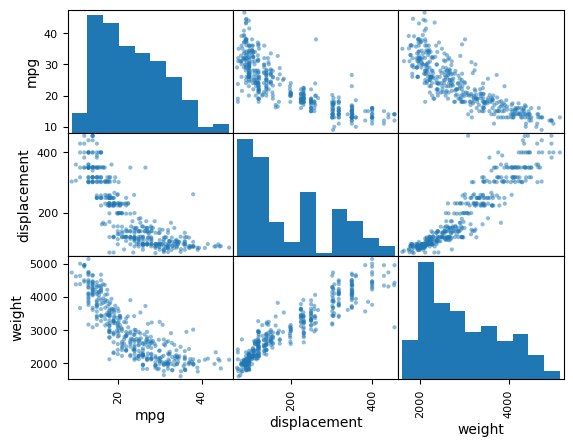
Numerical Summaries with DataFrame.describe() and Series.describe():
The DataFrame.describe() method provides descriptive statistics (count, mean, std, min, 25%, 50%, 75%, max) for each numerical column in a DataFrame.
Auto[
["mpg", "weight"]
].describe() # Descriptive statistics for "mpg" and "weight" columnsYou can also use .describe() on a single column (Pandas Series) to get descriptive statistics for that column.
Auto[
"cylinders"
].describe() # Descriptive statistics for "cylinders" column (categorical)
Auto["mpg"].describe() # Descriptive statistics for "mpg" column (numerical)count 392.000000
mean 23.445918
std 7.805007
min 9.000000
25% 17.000000
50% 22.750000
75% 29.000000
max 46.600000
Name: mpg, dtype: float64Pandas provides a rich set of tools for data visualization and numerical summarization, making it a powerful library for exploratory data analysis and data understanding.
Exiting Jupyter Notebook:
To exit Jupyter Notebook, go to the “File” menu in the Jupyter Notebook interface and select “Shut Down”. This will shut down the Jupyter server and close the notebook.
Congratulations on completing this introduction to Python for data science! You’ve learned fundamental Python concepts, explored NumPy for numerical computing, Matplotlib for plotting, and Pandas for data manipulation and analysis. These are essential building blocks for your journey into data science with Python. Continue practicing and exploring these libraries to deepen your skills.